前端代码仅展示部分。请在下方下载完整源码。
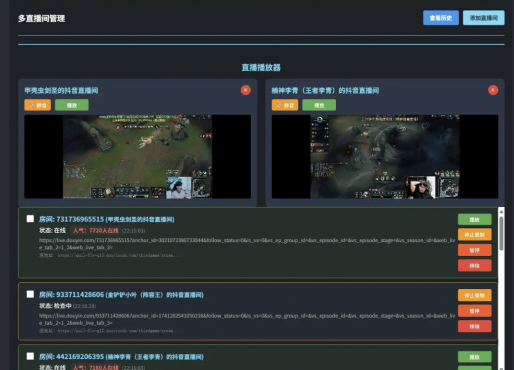
先看效果图:
MoonTV 抖音直播监控系统项目总结项目概述
本项目是一个抖音直播监控和录制系统,具有多直播间管理、自动轮询检查、直播录制等功能。前端使用Vue.js构建,后端使用Python Flask框架实现。
核心功能1. 多直播间管理
支持同时监控多个直播间的在线状态
自动轮询检查直播间状态(默认60秒间隔,可自定义)
显示直播间详细信息(房间ID、主播名、在线人数等)
- 直播录制功能
支持手动开始/停止录制
支持开播时自动录制(可选)
录制文件保存在本地 - 播放器功能
支持FLV直播流播放
页面内嵌式播放器(非弹窗)
支持多个播放器同时播放
播放器默认静音,点击播放后取消静音
播放器标题显示为主播名或房间ID - 批量操作
支持多选直播间
批量开始/停止录制
批量暂停/恢复轮询
批量移除直播间 - 历史记录
记录直播间轮询历史
显示主播名、直播间地址和时间信息
技术架构前端 (douyin-frontend)
框架:Vue.js 3
样式:Tailwind CSS
播放器:flv.js
构建工具:Vue CLI
后端 (douyin-backend)
框架:Python Flask
多线程:threading模块
HTTP请求:requests库
数据存储:JSON文件(saved_rooms.json, rooms_history.json)
主要文件结构
MoonTV-main/
├── douyin-frontend/
│ ├── src/
│ │ ├── App.vue (主应用组件)
│ │ ├── MultiRoomManager.vue (多直播间管理器)
│ │ └── assets/ (静态资源)
│ ├── public/
│ └── package.json
├── douyin-backend/
│ ├── app.py (主应用文件)
│ ├── saved_rooms.json (保存的直播间配置)
│ ├── rooms_history.json (轮询历史记录)
│ └── recordings/ (录制文件目录)
└── docs/
└── PROJECT_SUMMARY.md (项目说明文档)
API接口多直播间管理接口
GET /api/multi-poll/status - 获取所有直播间状态
POST /api/multi-poll/add - 添加直播间
POST /api/multi-poll/remove - 移除直播间
POST /api/multi-poll/start-record - 开始录制
POST /api/multi-poll/stop-record - 停止录制
POST /api/multi-poll/pause - 暂停轮询
POST /api/multi-poll/resume - 恢复轮询
GET /api/multi-poll/history - 获取历史记录
重要功能实现细节1. 暂停功能
暂停不仅停止录制,还会停止轮询检查,确保完全暂停直播间监控。 - 播放器实现
使用flv.js库支持FLV直播流播放
页面内嵌式播放器,支持多个播放器同时播放
默认静音状态,点击播放后取消静音
播放器标题显示为主播名或房间ID - 数据持久化
直播间配置保存在saved_rooms.json
轮询历史记录保存在rooms_history.json
录制文件保存在recordings目录下
启动方式
打开CMD
CD到项目目录下
后端服务
python app.py
前端服务
cd douyin-frontend
npm install # 首次运行需要安装依赖
npm run serve
项目特点
开箱即用,无需复杂配置
支持多直播间同时监控
自动录制功能
数据本地持久化存储
历史记录去重功能
支持手机端短链接解析
可获取直播间实时数据(如在线人数等)
使用场景
直播平台观众数据监控
网红经济数据分析系统
直播带货效果评估工具
多平台直播状态监控中心
后端:
from flask import Flask, request, jsonify
from flask_cors import CORS
import requests
import re
import time
import os
import subprocess
import threading
import json
import logging
from datetime import datetime
from functools import wraps
app = Flask(name)
CORS(app, resources={r"/*": {"origins": ["http://127.0.0.1:8080", "http://localhost:8080"]}}, supports_credentials=True)
配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(name)
全局变量
recording_sessions = {}
recording_lock = threading.Lock()
新增:多直播间轮询管理
polling_sessions = {}
polling_lock = threading.Lock()
异常处理装饰器
def handle_exceptions(func):
@wraps(func)
def wrapper(*args, *kwargs):
try:
return func(args, **kwargs)
except Exception as e:
logger.error(f"函数 {func.name} 执行失败: {str(e)}", exc_info=True)
return jsonify({
'success': False,
'message': f'服务器内部错误: {str(e)}'
}), 500
return wrapper
def get_real_stream_url(url, max_retries=3):
"""
解析抖音直播链接,获取真实的直播流地址
:param url: 抖音直播链接
:param max_retries: 最大重试次数
:return: 直播流地址或 None
"""
# 存储捕获到的直播流地址的变量,放在循环外部以便在所有尝试结束后仍能访问
captured_stream_urls = []
for attempt in range(max_retries):
try:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
# 启动浏览器(无头模式)
browser = p.chromium.launch(headless=True)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
viewport={"width": 1920, "height": 1080}
)
page = context.new_page()
# 创建一个事件,用于在捕获到直播流地址时通知主线程
stream_captured_event = threading.Event()
# 处理URL格式
if not url.startswith("http"):
url = f"https://live.douyin.com/{url}"
logger.info(f"转换为完整URL: {url}")
# 访问直播页面
logger.info(f"[尝试{attempt + 1}] 开始访问页面: {url}")
page.goto(url, timeout=30000, wait_until="domcontentloaded")
# 定义在捕获到直播流地址时的处理函数
def on_stream_captured(url):
logger.info(f"[尝试{attempt + 1}] 成功捕获到直播流地址: {url}")
if url not in captured_stream_urls:
captured_stream_urls.append(url)
logger.info(f"[尝试{attempt + 1}] 已保存直播流地址,当前共 {len(captured_stream_urls)} 个")
# 立即设置事件,通知主线程已捕获到直播流地址
stream_captured_event.set()
logger.info(f"[尝试{attempt + 1}] 已通知主线程捕获到直播流地址")
# 添加网络请求监听函数
def handle_response(response):
try:
response_url = response.url
if (response_url.endswith('.m3u8') or
response_url.endswith('.flv') or
('.flv?' in response_url) or
('.m3u8?' in response_url) or
('douyincdn.com' in response_url and ('stream' in response_url or 'pull' in response_url)) or
('video' in response.headers.get('content-type', '') and not response_url.endswith('.mp4'))):
on_stream_captured(response_url)
except Exception as e:
logger.warning(f"处理响应失败: {e}")
page.on("response", handle_response)
# 直接等待网络请求,最多等待10秒
max_wait_time = 10
logger.info(f"[尝试{attempt + 1}] 开始等待直播流地址捕获...")
# 等待事件或超时
for elapsed_time in range(1, max_wait_time + 1):
# 先检查是否已经捕获到直播流地址
if captured_stream_urls:
logger.info(f"[尝试{attempt + 1}] 检测到已捕获 {len(captured_stream_urls)} 个直播流地址")
context.close()
return captured_stream_urls[0] # 返回第一个捕获到的地址
# 等待事件通知
if stream_captured_event.wait(1): # 等待1秒
logger.info(f"[尝试{attempt + 1}] 在 {elapsed_time} 秒后收到直播流地址捕获通知")
context.close()
return captured_stream_urls[0] # 返回第一个捕获到的地址
# 每2秒输出一次等待日志
if elapsed_time % 2 == 0:
logger.info(f"[尝试{attempt + 1}] 等待网络请求中... ({elapsed_time}/{max_wait_time}秒)")
# 等待结束后最后检查一次变量
if captured_stream_urls: # 变量不为空
logger.info(f"[尝试{attempt + 1}] 等待结束后发现 {len(captured_stream_urls)} 个直播流地址")
context.close()
return captured_stream_urls[0]
else:
logger.warning(f"[尝试{attempt + 1}] 等待结束后仍未捕获到直播流地址")
# 保存页面内容用于调试
try:
with open('debug_page_content.html', 'w', encoding='utf-8') as f:
f.write(page.content())
except Exception as e:
logger.warning(f"保存调试文件失败: {e}")
# 最后一次检查是否捕获到直播流地址
if captured_stream_urls:
logger.info(f"[尝试{attempt + 1}] 关闭浏览器前发现已捕获到直播流地址")
context.close()
return captured_stream_urls[0]
context.close()
if attempt < max_retries - 1:
logger.info(f"第 {attempt + 1} 次尝试失败,准备第 {attempt + 2} 次尝试...")
time.sleep(2) # 重试前等待
except Exception as e:
logger.error(f"解析直播流地址失败 (尝试 {attempt + 1}): {str(e)}")
# 即使发生异常,也检查是否已经捕获到直播流地址
if captured_stream_urls:
logger.info(f"[尝试{attempt + 1}] 尽管发生异常,但已捕获到直播流地址")
return captured_stream_urls[0]
if attempt < max_retries - 1:
time.sleep(2)
continue
# 最后一次检查是否有捕获到的直播流地址
if captured_stream_urls:
logger.info(f"虽然所有 {max_retries} 次尝试报告失败,但已捕获到 {len(captured_stream_urls)} 个直播流地址")
return captured_stream_urls[0]
logger.error(f"所有 {max_retries} 次尝试均失败,未能捕获到直播流地址")
return Nonedef parse_viewer_count(text):
"""
解析观看人数文本为数字
例: "32人在线" -> 32, "1.2万人在看" -> 12000, "5000人在看" -> 5000
"""
try:
移除常见的文字,保留数字和单位
clean_text = re.sub(r'[人在看观气线众]', '', text)
# 查找数字和单位
match = re.search(r'(\d+(?:\.\d+)?)\s*([万w])?', clean_text, re.IGNORECASE)
if match:
number = float(match.group(1))
unit = match.group(2)
# 如果有"万"或"w"单位,乘以10000
if unit and unit.lower() in ['万', 'w']:
number *= 10000
return int(number)
except Exception as e:
logger.debug(f"解析观看人数失败: {e}")
return 0def get_live_room_info(url, max_retries=3):
"""
获取直播间详细信息,包括在线人数
:param url: 抖音直播链接
:param max_retries: 最大重试次数
:return: 包含在线人数等信息的字典
"""
room_info = {
'online_count': 0,
'is_live': False,
'stream_url': None,
'room_title': '',
'anchor_name': '',
'room_id': '',
'viewer_count_text': '' # 显示的观看人数文本(如"1.2万人在看")
}
for attempt in range(max_retries):
try:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(headless=True)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
viewport={"width": 1920, "height": 1080}
)
page = context.new_page()
# 存储捕获的数据
captured_data = {
'stream_urls': [],
'api_responses': []
}
# 处理URL格式
if not url.startswith("http"):
url = f"https://live.douyin.com/{url}"
logger.info(f"[尝试{attempt + 1}] 开始获取直播间信息: {url}")
# 监听网络请求,捕获API响应
def handle_response(response):
try:
response_url = response.url
# 捕获直播流地址
if (response_url.endswith('.m3u8') or
response_url.endswith('.flv') or
('.flv?' in response_url) or
('.m3u8?' in response_url) or
('douyincdn.com' in response_url and ('stream' in response_url or 'pull' in response_url))):
captured_data['stream_urls'].append(response_url)
logger.info(f"捕获到直播流: {response_url}")
# 捕获包含直播间信息的API响应
if ('webcast/room/' in response_url or
'webcast/web/' in response_url or
'/api/live_data/' in response_url or
'room_id' in response_url):
try:
if response.status == 200:
response_json = response.json()
captured_data['api_responses'].append({
'url': response_url,
'data': response_json
})
logger.info(f"捕获到API响应: {response_url}")
except Exception as json_error:
logger.debug(f"API响应解析失败: {json_error}")
except Exception as e:
logger.debug(f"处理响应失败: {e}")
page.on("response", handle_response)
# 访问直播页面
page.goto(url, timeout=30000, wait_until="domcontentloaded")
# 等待页面加载并捕获网络请求
time.sleep(5)
# 尝试从页面元素获取信息
try:
# 方法1: 通过页面元素获取在线人数 - 更精确的选择器
online_selectors = [
'[data-e2e="living-avatar-name"]',
'[class*="viewer"][class*="count"]',
'[class*="online"][class*="count"]',
'[class*="watching"][class*="count"]',
'span:has-text("在线观众")',
'span:has-text("观众")',
'div:has-text("在线观众")',
'.webcast-chatroom___content span'
]
viewer_text = ""
# 首先尝试找到"在线观众"相关的元素
for selector in online_selectors:
try:
elements = page.query_selector_all(selector)
for element in elements:
text = element.inner_text().strip()
# 更严格的匹配条件,只要包含"在线观众"或纯数字的
if ('在线观众' in text or '观众' in text) and any(c.isdigit() for c in text):
# 提取"在线观众 · 32"这样的格式
import re
match = re.search(r'在线观众[\s·]*([\d,]+)', text)
if match:
viewer_text = f"{match.group(1)}人在线"
logger.info(f"找到在线观众数: {viewer_text}")
break
# 或者提取"观众 32"这样的格式
match = re.search(r'观众[\s·]*([\d,]+)', text)
if match:
viewer_text = f"{match.group(1)}人在线"
logger.info(f"找到观众数: {viewer_text}")
break
if viewer_text:
break
except Exception as e:
logger.debug(f"选择器 {selector} 解析失败: {e}")
# 如果没找到,尝试从页面内容中提取"在线观众"信息
if not viewer_text:
page_content = page.content()
# 使用正则表达式精确匹配"在线观众 · 数字"格式
patterns = [
r'在线观众[\s·]*([\d,]+)',
r'观众[\s·]*([\d,]+)',
r'(\d+)\s*人在线',
r'(\d+)\s*观看'
]
for pattern in patterns:
matches = re.findall(pattern, page_content)
if matches:
# 取第一个匹配的数字
count_str = matches[0].replace(',', '') # 移除千分位逗号
try:
count = int(count_str)
viewer_text = f"{count}人在线"
logger.info(f"通过正则表达式获取到观众数: {viewer_text}")
break
except ValueError:
continue
# 解析人数文本为数字
if viewer_text:
room_info['viewer_count_text'] = viewer_text
online_count = parse_viewer_count(viewer_text)
room_info['online_count'] = online_count
except Exception as e:
logger.warning(f"从页面元素获取在线人数失败: {e}")
# 方法2: 从API响应中提取信息
for api_resp in captured_data['api_responses']:
try:
data = api_resp['data']
# 抖音API响应结构可能包含以下字段
if 'data' in data:
room_data = data['data']
# 在线人数
if 'user_count' in room_data:
room_info['online_count'] = max(room_info['online_count'], room_data['user_count'])
elif 'stats' in room_data and 'user_count' in room_data['stats']:
room_info['online_count'] = max(room_info['online_count'], room_data['stats']['user_count'])
elif 'room_view_stats' in room_data:
room_info['online_count'] = max(room_info['online_count'], room_data['room_view_stats'].get('display_long', 0))
# 直播状态
if 'status' in room_data:
room_info['is_live'] = room_data['status'] == 2 # 2通常表示正在直播
# 房间标题
if 'title' in room_data:
room_info['room_title'] = room_data['title']
# 主播名称
if 'owner' in room_data and 'nickname' in room_data['owner']:
room_info['anchor_name'] = room_data['owner']['nickname']
# 房间ID
if 'id_str' in room_data:
room_info['room_id'] = room_data['id_str']
except Exception as e:
logger.debug(f"解析API响应失败: {e}")
# 设置直播流地址
if captured_data['stream_urls']:
room_info['stream_url'] = captured_data['stream_urls'][0]
room_info['is_live'] = True
# 如果没有从API获取到在线人数,尝试页面内容检测
if room_info['online_count'] == 0 and not room_info['viewer_count_text']:
try:
page_content = page.content()
# 使用更精确的正则表达式从页面内容中提取人数
patterns = [
r'在线观众[\s·]*([\d,]+)', # "在线观众 · 32"
r'观众[\s·]*([\d,]+)', # "观众 32"
r'"user_count["\s]*:\s*(\d+)',
r'"viewer_count["\s]*:\s*(\d+)',
]
for pattern in patterns:
matches = re.findall(pattern, page_content, re.IGNORECASE)
if matches:
try:
count_str = matches[0].replace(',', '') # 移除千分位逗号
count = int(count_str)
room_info['online_count'] = count
room_info['viewer_count_text'] = f"{count}人在线"
logger.info(f"通过正则表达式获取到人数: {room_info['online_count']}")
break
except ValueError:
continue
except Exception as e:
logger.warning(f"页面内容解析失败: {e}")
context.close()
# 如果获取到了有效信息就返回
if room_info['online_count'] > 0 or room_info['stream_url'] or room_info['is_live']:
logger.info(f"成功获取直播间信息: 在线人数={room_info['online_count']}, 直播状态={room_info['is_live']}")
return room_info
except Exception as e:
logger.error(f"获取直播间信息失败 (尝试 {attempt + 1}): {str(e)}")
if attempt < max_retries - 1:
time.sleep(2)
continue
logger.error(f"所有 {max_retries} 次尝试均失败,无法获取直播间信息")
return room_info@app.route('/')
@handle_exceptions
def home():
return jsonify({
'message': '抖音直播解析后端服务已启动',
'api': ['/api/parse', '/api/room-info', '/api/monitor', '/api/record/start', '/api/record/stop', '/api/record/status']
})
@app.route('/api/parse', methods=['POST'])
@handle_exceptions
def parse_live_stream():
data = request.get_json()
url = data.get('url')
if not url:
return jsonify({
'success': False,
'message': '无效的直播链接或主播ID'
})
# 处理不同格式的输入
processed_url = url.strip()
logger.info(f"收到解析请求,原始输入: {processed_url}")
# 1. 检查是否是纯数字(主播ID)
if re.match(r'^\d+$', processed_url):
logger.info(f"检测到主播ID格式: {processed_url}")
room_id = processed_url
full_url = f"https://live.douyin.com/{room_id}"
# 2. 检查是否是完整的抖音直播URL
elif "douyin.com" in processed_url:
logger.info(f"检测到抖音URL格式: {processed_url}")
# 提取房间号
if "/user/" in processed_url:
# 用户主页URL
logger.info("检测到用户主页URL,尝试提取用户ID")
user_id_match = re.search(r'/user/([^/?]+)', processed_url)
if user_id_match:
room_id = user_id_match.group(1)
full_url = f"https://live.douyin.com/{room_id}"
else:
return jsonify({
'success': False,
'message': '无法从用户主页URL提取用户ID'
})
else:
# 直播间URL
room_id_match = re.search(r'live\.douyin\.com/([^/?]+)', processed_url)
if room_id_match:
room_id = room_id_match.group(1)
full_url = f"https://live.douyin.com/{room_id}"
else:
# 尝试直接使用
room_id = processed_url
full_url = processed_url
# 3. 其他格式(可能是短链接或其他标识符)
else:
logger.info(f"未识别的URL格式,尝试直接使用: {processed_url}")
room_id = processed_url
full_url = processed_url
logger.info(f"处理后的房间ID: {room_id}, 完整URL: {full_url}")
# 调用解析函数获取直播流地址
real_stream_url = get_real_stream_url(full_url)
if real_stream_url:
logger.info(f"成功解析直播流地址: {real_stream_url}")
return jsonify({
'success': True,
'streamUrl': real_stream_url,
'roomId': room_id,
'fullUrl': full_url
})
else:
logger.warning(f"无法解析直播流地址,输入: {processed_url}")
return jsonify({
'success': False,
'message': '无法解析直播链接,请确认主播是否开播'
})新增:获取直播间详细信息的API接口
@app.route('/api/room-info', methods=['POST'])
@handle_exceptions
def get_room_info():
"""获取直播间详细信息,包括在线人数"""
data = request.get_json()
url = data.get('url')
if not url:
return jsonify({
'success': False,
'message': '无效的直播链接或主播 ID'
})
# 处理URL格式
processed_url = url.strip()
logger.info(f"收到直播间信息请求: {processed_url}")
# URL格式处理逻辑(与parse_live_stream相同)
if re.match(r'^\d+$', processed_url):
full_url = f"https://live.douyin.com/{processed_url}"
elif "douyin.com" in processed_url:
full_url = processed_url
else:
full_url = processed_url
# 获取直播间信息
room_info = get_live_room_info(full_url)
if room_info['is_live'] or room_info['online_count'] > 0:
return jsonify({
'success': True,
'data': {
'online_count': room_info['online_count'],
'viewer_count_text': room_info['viewer_count_text'],
'is_live': room_info['is_live'],
'stream_url': room_info['stream_url'],
'room_title': room_info['room_title'],
'anchor_name': room_info['anchor_name'],
'room_id': room_info['room_id']
}
})
else:
return jsonify({
'success': False,
'message': '直播间未开播或无法获取信息',
'data': room_info
})def get_anchor_info(anchor_id, max_retries=2):
"""
获取主播信息(名字、直播状态等)
:param anchor_id: 主播ID
:param max_retries: 最大重试次数
:return: dict 包含 {"is_live": bool, "name": str, "title": str}
"""
for attempt in range(max_retries):
try:
from playwright.sync_api import sync_playwright
import random
with sync_playwright() as p:
# 启动浏览器(无头模式)
browser = p.chromium.launch(headless=True)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36",
extra_http_headers={
"Referer": "https://www.douyin.com/",
"Accept-Language": "zh-CN,zh;q=0.9"
},
viewport={"width": 1920, "height": 1080},
java_script_enabled=True
)
page = context.new_page()
# 随机延迟(1-3秒),模拟人类操作
time.sleep(random.uniform(1, 3))
# 访问直播间页面
try:
# 处理URL格式,确保不重复添加域名
if anchor_id.startswith("https://live.douyin.com/"):
url = anchor_id
room_id = anchor_id.split("/")[-1]
else:
url = f"https://live.douyin.com/{anchor_id}"
room_id = anchor_id
logger.info(f"[尝试{attempt + 1}] 开始访问直播间页面: {url}")
page.goto(url, timeout=30000, wait_until="domcontentloaded")
logger.info(f"[尝试{attempt + 1}] 成功访问直播间页面")
except Exception as e:
if "Timeout" in str(e):
logger.warning(f"[尝试{attempt + 1}] 页面加载超时,继续处理")
else:
logger.error(f"[尝试{attempt + 1}] 访问直播间页面失败: {e}")
context.close()
continue
# 等待页面加载
try:
logger.info(f"[尝试{attempt + 1}] 等待页面关键元素加载...")
page.wait_for_selector("body", timeout=10000)
# 额外等待,确保页面完全加载
time.sleep(3)
except Exception as wait_e:
logger.warning(f"[尝试{attempt + 1}] 等待元素失败: {wait_e},继续处理")
# 获取页面内容
content = page.content()
logger.info(f"[尝试{attempt + 1}] 页面内容长度: {len(content)} 字符")
# 提取主播信息
anchor_info = {
"is_live": False,
"name": f"anchor_{room_id}", # 默认名字
"title": ""
}
# 尝试获取主播名字
logger.info(f"[尝试{attempt + 1}] 开始尝试获取主播名字...")
# 策略1: 尝试从页面标题获取(优先策略)
try:
title = page.title()
logger.info(f"[尝试{attempt + 1}] 页面标题: {title}")
# 抖音直播间标题格式分析
if title and title != "抖音直播":
# 格式1: "主播名字的直播间"
if "的直播间" in title:
name_from_title = title.split("的直播间")[0].strip()
if name_from_title and len(name_from_title) < 50 and name_from_title != room_id:
anchor_info["name"] = name_from_title
logger.info(f"[尝试{attempt + 1}] 从页面标题获取到主播名字: {name_from_title}")
# 格式2: "主播名字 - 抖音直播"
elif " - 抖音" in title or " - 直播" in title:
parts = title.split(" - ")
if len(parts) > 0:
potential_name = parts[0].strip()
if potential_name and len(potential_name) < 50 and potential_name != room_id:
anchor_info["name"] = potential_name
logger.info(f"[尝试{attempt + 1}] 从页面标题解析到主播名字: {potential_name}")
# 格式3: "主播名字正在直播"
elif "正在直播" in title:
name_from_title = title.replace("正在直播", "").strip()
if name_from_title and len(name_from_title) < 50 and name_from_title != room_id:
anchor_info["name"] = name_from_title
logger.info(f"[尝试{attempt + 1}] 从'正在直播'标题获取到主播名字: {name_from_title}")
# 格式4: 直接使用标题(如果长度合理)
elif len(title) < 50 and title != room_id and not any(word in title.lower() for word in ["douyin", "live", "直播"]):
anchor_info["name"] = title
logger.info(f"[尝试{attempt + 1}] 直接使用页面标题作为主播名字: {title}")
except Exception as title_e:
logger.debug(f"[尝试{attempt + 1}] 从标题获取名字失败: {title_e}")
# 策略2: 尝试从页面元素获取(如果标题没有找到合适的名字)
if anchor_info["name"] == f"anchor_{room_id}":
try:
logger.info(f"[尝试{attempt + 1}] 尝试从页面元素获取主播名字...")
# 更新的选择器列表
name_selectors = [
"[data-e2e='living-avatar-name']",
"[data-e2e='user-info-name']",
".webcast-avatar-info__name",
".live-user-info .name",
".live-user-name",
".user-name",
".anchor-name",
"[class*='name']",
"h3",
".nickname"
]
for selector in name_selectors:
try:
name_element = page.query_selector(selector)
if name_element:
name_text = name_element.inner_text().strip()
if name_text and len(name_text) < 50 and name_text != room_id and not name_text.isdigit():
anchor_info["name"] = name_text
logger.info(f"[尝试{attempt + 1}] 使用选择器 {selector} 获取到主播名字: {name_text}")
break
except Exception as sel_e:
logger.debug(f"[尝试{attempt + 1}] 选择器 {selector} 失败: {sel_e}")
continue
except Exception as e:
logger.debug(f"[尝试{attempt + 1}] 从页面元素获取名字失败: {e}")
# 策略3: 从页面JSON数据中提取(如果前面都没找到)
if anchor_info["name"] == f"anchor_{room_id}":
try:
logger.info(f"[尝试{attempt + 1}] 尝试从页面JSON数据获取主播名字...")
content_text = page.content()
# 多种JSON字段模式
json_patterns = [
r'"nickname"\s*:\s*"([^"]+)"',
r'"displayName"\s*:\s*"([^"]+)"',
r'"userName"\s*:\s*"([^"]+)"',
r'"ownerName"\s*:\s*"([^"]+)"',
r'"anchorName"\s*:\s*"([^"]+)"',
r'"user_name"\s*:\s*"([^"]+)"',
r'"anchor_info"[^}]*"nickname"\s*:\s*"([^"]+)"'
]
import re as regex_re
for pattern in json_patterns:
matches = regex_re.findall(pattern, content_text)
for match in matches:
if match and len(match) < 50 and match != room_id and not match.isdigit():
# 过滤掉明显不是名字的内容
if not any(word in match.lower() for word in ['http', 'www', '.com', 'live', 'stream']):
anchor_info["name"] = match
logger.info(f"[尝试{attempt + 1}] 从页面JSON数据获取到主播名字: {match} (模式: {pattern})")
break
if anchor_info["name"] != f"anchor_{room_id}":
break
except Exception as content_e:
logger.debug(f"[尝试{attempt + 1}] 从页面内容获取名字失败: {content_e}")
# 策略4: 最后的降级处理(使用更友好的默认名字)
if anchor_info["name"] == f"anchor_{room_id}":
# 尝试从room_id中提取可能的用户名部分
if len(room_id) > 8: # 如果room_id足够长,尝试截取前8位作为更简洁的标识
anchor_info["name"] = f"主播{room_id[:8]}"
else:
anchor_info["name"] = f"主播{room_id}"
logger.info(f"[尝试{attempt + 1}] 使用降级处理的默认名字: {anchor_info['name']}")
# 检查直播状态
stream_urls = []
def handle_response(response):
url = response.url
if ((url.endswith('.flv') or url.endswith('.m3u8')) and
not url.endswith('.mp4') and
('pull-' in url or 'douyincdn.com' in url)):
stream_urls.append(url)
logger.info(f"[尝试{attempt + 1}] 捕获到直播流: {url}")
page.on("response", handle_response)
# 等待更多网络请求
logger.info(f"[尝试{attempt + 1}] 等待网络请求...")
time.sleep(3)
# 多种方式检测直播状态
anchor_info["is_live"] = (
"直播中" in content or
"正在直播" in content or
"live_no_stream" not in content.lower() and "直播" in content or
"live" in content.lower() or
page.query_selector(".webcast-chatroom___enter-done") is not None or
page.query_selector(".live-room") is not None or
page.query_selector("video[src*='.m3u8']") is not None or
page.query_selector("video[src*='.flv']") is not None or
page.query_selector("video[src*='douyincdn.com']") is not None or
len(stream_urls) > 0
)
context.close()
logger.info(f"[尝试{attempt + 1}] 最终获取结果 - 主播名字: {anchor_info['name']}, 直播状态: {'在线' if anchor_info['is_live'] else '离线'}")
return anchor_info
except Exception as e:
logger.error(f"获取主播信息失败 (尝试 {attempt + 1}): {str(e)}")
if attempt < max_retries - 1:
time.sleep(2)
continue
logger.error(f"所有 {max_retries} 次尝试均失败,返回默认结果")
# 最终降级处理
fallback_name = f"主播{anchor_id[:8]}" if len(str(anchor_id)) > 8 else f"主播{anchor_id}"
return {"is_live": False, "name": fallback_name, "title": ""}def check_anchor_status(anchor_id, max_retries=2):
"""
检查主播是否开播
:param anchor_id: 主播ID
:param max_retries: 最大重试次数
:return: True(开播)/False(未开播)
"""
for attempt in range(max_retries):
try:
from playwright.sync_api import sync_playwright
import random
with sync_playwright() as p:
# 启动浏览器(无头模式)
browser = p.chromium.launch(headless=True)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
extra_http_headers={
"Referer": "https://www.douyin.com/",
"Accept-Language": "zh-CN,zh;q=0.9"
},
viewport={"width": 1920, "height": 1080},
java_script_enabled=True
)
page = context.new_page()
# 随机延迟(1-3秒),模拟人类操作
time.sleep(random.uniform(1, 3))
# 访问直播间页面
try:
# 处理URL格式,确保不重复添加域名
if anchor_id.startswith("https://live.douyin.com/"):
url = anchor_id
room_id = anchor_id.split("/")[-1]
else:
url = f"https://live.douyin.com/{anchor_id}"
room_id = anchor_id
page.goto(url, timeout=30000, wait_until="domcontentloaded")
logger.info(f"成功访问直播间页面: {url}")
except Exception as e:
if "Timeout" in str(e):
logger.warning(f"页面加载超时,继续处理")
else:
logger.error(f"访问直播间页面失败: {e}")
context.close()
continue
# 等待页面加载
try:
page.wait_for_selector("video, .live-room, .webcast-chatroom", timeout=10000)
except:
logger.warning("未找到关键元素,继续处理")
# 获取页面内容
content = page.content()
# 检查直播状态
stream_urls = []
def handle_response(response):
url = response.url
if ((url.endswith('.flv') or url.endswith('.m3u8')) and
not url.endswith('.mp4') and
('pull-' in url or 'douyincdn.com' in url)):
stream_urls.append(url)
logger.info(f"捕获到直播流: {url}")
page.on("response", handle_response)
# 等待更多网络请求
time.sleep(3)
# 多种方式检测直播状态
is_live = (
"直播中" in content or
"正在直播" in content or
"直播" in content or
"live" in content.lower() or
page.query_selector(".webcast-chatroom___enter-done") is not None or
page.query_selector(".live-room") is not None or
page.query_selector("video[src*='.m3u8']") is not None or
page.query_selector("video[src*='.flv']") is not None or
page.query_selector("video[src*='douyincdn.com']") is not None or
len(stream_urls) > 0 or
any("live.douyin.com" in url for url in stream_urls)
)
context.close()
if is_live:
logger.info(f"主播 {anchor_id} 正在直播")
if stream_urls:
logger.info(f"捕获到直播流地址: {stream_urls[0]}")
else:
logger.info(f"主播 {anchor_id} 未开播")
return is_live
except Exception as e:
logger.error(f"检查主播状态失败 (尝试 {attempt + 1}): {str(e)}")
if attempt < max_retries - 1:
time.sleep(2)
continue
logger.error(f"所有 {max_retries} 次尝试均失败")
return False@app.route('/api/monitor', methods=['POST'])
@handle_exceptions
def monitor_live_stream():
data = request.get_json()
anchor_id = data.get('anchor_id')
max_wait_minutes = data.get('max_wait', 5) # 默认最多等待5分钟
check_interval = data.get('interval', 30) # 默认每30秒检查一次
logger.info(f"收到监控请求,主播ID: {anchor_id}, 最长等待: {max_wait_minutes}分钟, 轮询地址: https://live.douyin.com/{anchor_id}")
if not anchor_id:
logger.warning("无效的主播ID")
return jsonify({
'success': False,
'message': '无效的主播ID'
})
max_checks = (max_wait_minutes * 60) // check_interval
checks_done = 0
# 轮询检查主播状态
while checks_done < max_checks:
checks_done += 1
logger.info(f"第 {checks_done}/{max_checks} 次检查主播 {anchor_id} 状态")
is_live = check_anchor_status(anchor_id)
if is_live:
logger.info(f"主播 {anchor_id} 正在直播,开始解析直播流地址")
# 获取直播流地址
stream_url = get_real_stream_url(f"https://live.douyin.com/{anchor_id}")
if stream_url:
logger.info(f"成功获取直播流地址: {stream_url}")
return jsonify({
'success': True,
'status': 'live',
'streamUrl': stream_url,
'checks_performed': checks_done
})
else:
logger.warning("无法解析直播流地址")
return jsonify({
'success': False,
'message': '无法解析直播流地址',
'checks_performed': checks_done
})
else:
logger.info(f"主播 {anchor_id} 未开播,等待下一次检查")
# 如果达到最大检查次数,返回未开播状态
if checks_done >= max_checks:
logger.info(f"监控超时,主播 {anchor_id} 在 {max_wait_minutes} 分钟内未开播")
return jsonify({
'success': True,
'status': 'not_live',
'message': f'主播在 {max_wait_minutes} 分钟内未开播',
'checks_performed': checks_done
})
time.sleep(check_interval)
logger.warning("监控循环异常结束")
return jsonify({
'success': False,
'message': '监控异常结束',
'checks_performed': checks_done
})class MultiRoomPoller:
"""多直播间轮询管理器"""
def __init__(self):
self.polling_rooms = {} # 存储轮询中的直播间
self.polling_history = [] # 存储历史轮询记录
self.lock = threading.Lock()
self.running = True
self.max_history_records = 1000 # 最大历史记录数
self.rooms_file = 'saved_rooms.json' # 本地存储文件
self.history_file = 'rooms_history.json' # 历史记录文件
# 启动时加载已保存的直播间
self._load_rooms_from_file()
self._load_history_from_file()
def add_room(self, room_id, room_url, check_interval=60, auto_record=False):
"""添加直播间到轮询列表"""
with self.lock:
if room_id not in self.polling_rooms:
# 不再在这里添加历史记录,等待轮询线程获取到真实主播名字后再添加
self.polling_rooms[room_id] = {
'room_url': room_url,
'room_id': room_id,
'check_interval': check_interval,
'auto_record': auto_record,
'status': 'waiting', # waiting, checking, live, offline, paused
'last_check': None,
'stream_url': None,
'recording_session_id': None,
'thread': None,
'anchor_name': f'anchor_{room_id}', # 新增:主播名字
'live_title': '', # 新增:直播标题
'added_time': datetime.now(), # 新增:添加时间
'history_added': False, # 新增:标记是否已添加历史记录
'online_count': 0, # 新增:在线人数
'viewer_count_text': '' # 新增:观看人数文本
}
# 启动轮询线程
thread = threading.Thread(
target=self._poll_room,
args=(room_id,),
daemon=True
)
thread.start()
self.polling_rooms[room_id]['thread'] = thread
logger.info(f"已添加直播间 {room_id} 到轮询列表")
# 保存到本地文件
self._save_rooms_to_file()
return True
else:
logger.warning(f"直播间 {room_id} 已在轮询列表中")
return False
def remove_room(self, room_id):
"""从轮询列表移除直播间"""
with self.lock:
if room_id in self.polling_rooms:
room_info = self.polling_rooms[room_id]
# 记录到历史
self._add_to_history(
room_id,
room_info['room_url'],
'',
'',
room_info.get('anchor_name', f'anchor_{room_id}')
)
# 停止录制(如果正在录制)
if self.polling_rooms[room_id]['recording_session_id']:
self._stop_recording(room_id)
# 标记线程停止
self.polling_rooms[room_id]['status'] = 'stopped'
del self.polling_rooms[room_id]
# 保存到本地文件
self._save_rooms_to_file()
logger.info(f"已从轮询列表移除直播间 {room_id}")
return True
return False
def pause_room(self, room_id):
"""暂停指定直播间的轮询"""
with self.lock:
if room_id in self.polling_rooms:
# 如果已经在暂停状态,返回False
if self.polling_rooms[room_id]['status'] == 'paused':
return False
# 更新状态为暂停
self.polling_rooms[room_id]['status'] = 'paused'
logger.info(f"已暂停直播间 {room_id} 的轮询")
return True
return False
def resume_room(self, room_id):
"""恢复指定直播间的轮询"""
with self.lock:
if room_id in self.polling_rooms:
# 如果不在暂停状态,返回False
if self.polling_rooms[room_id]['status'] != 'paused':
return False
# 更新状态为等待
self.polling_rooms[room_id]['status'] = 'waiting'
logger.info(f"已恢复直播间 {room_id} 的轮询")
return True
return False
def _poll_room(self, room_id):
"""单个直播间轮询逻辑"""
while self.running:
try:
with self.lock:
if room_id not in self.polling_rooms:
break
room_info = self.polling_rooms[room_id]
# 检查是否暂停
if room_info['status'] == 'paused':
# 如果暂停,等待一段时间后继续检查
time.sleep(5)
continue
if room_info['status'] == 'stopped':
break
# 更新状态为检查中
with self.lock:
self.polling_rooms[room_id]['status'] = 'checking'
self.polling_rooms[room_id]['last_check'] = datetime.now()
# 检查直播状态并获取主播信息
anchor_info = get_anchor_info(room_info['room_id'])
is_live = anchor_info['is_live']
# 获取直播间详细信息(包括在线人数)
room_detail_info = {'online_count': 0, 'viewer_count_text': ''}
if is_live:
try:
# 调用get_live_room_info获取在线人数信息
room_detail_info = get_live_room_info(room_info['room_url'])
logger.info(f"直播间 {room_id} 在线人数: {room_detail_info.get('online_count', 0)}")
except Exception as e:
logger.warning(f"获取直播间 {room_id} 在线人数失败: {e}")
# 更新主播信息和在线人数
with self.lock:
self.polling_rooms[room_id]['anchor_name'] = anchor_info['name']
self.polling_rooms[room_id]['live_title'] = anchor_info['title']
self.polling_rooms[room_id]['online_count'] = room_detail_info.get('online_count', 0)
self.polling_rooms[room_id]['viewer_count_text'] = room_detail_info.get('viewer_count_text', '')
# 如果还没有添加历史记录,现在添加一条记录
if not self.polling_rooms[room_id].get('history_added', False):
self._add_to_history(
room_id,
room_info['room_url'],
'',
'',
anchor_info['name']
)
self.polling_rooms[room_id]['history_added'] = True
if is_live:
logger.info(f"检测到直播间 {room_id} 正在直播")
# 记录状态变化到历史(如果之前不是直播状态)
# 简化版:不记录状态变化
# 解析直播流地址
stream_url = get_real_stream_url(room_info['room_url'])
if stream_url:
with self.lock:
self.polling_rooms[room_id]['status'] = 'live'
self.polling_rooms[room_id]['stream_url'] = stream_url
# 如果启用自动录制且未在录制
if (room_info['auto_record'] and
not room_info['recording_session_id']):
self._start_recording(room_id, stream_url)
# 简化版:不记录自动录制开始
else:
logger.warning(f"直播间 {room_id} 在线但无法获取流地址")
with self.lock:
old_status = self.polling_rooms[room_id]['status']
self.polling_rooms[room_id]['status'] = 'live_no_stream'
# 简化版:不记录状态变化
# 如果之前在录制,停止录制(直播结束无流)
if room_info['recording_session_id']:
self._stop_recording(room_id)
logger.info(f"直播间 {room_id} 直播结束无流,已停止录制")
# 简化版:不记录停止录制
else:
# 直播间离线
with self.lock:
old_status = self.polling_rooms[room_id]['status']
self.polling_rooms[room_id]['status'] = 'offline'
self.polling_rooms[room_id]['stream_url'] = None
# 简化版:不记录状态变化
# 如果之前在录制,停止录制
if room_info['recording_session_id']:
self._stop_recording(room_id)
logger.info(f"直播间 {room_id} 离线,已停止录制")
# 简化版:不记录停止录制
# 等待下次检查
time.sleep(room_info['check_interval'])
except Exception as e:
logger.error(f"轮询直播间 {room_id} 异常: {str(e)}")
with self.lock:
if room_id in self.polling_rooms:
self.polling_rooms[room_id]['status'] = 'error'
time.sleep(30) # 出错时等待30秒后重试
def _start_recording(self, room_id, stream_url):
"""启动录制"""
try:
# 获取主播名字用于文件命名
with self.lock:
anchor_name = self.polling_rooms[room_id].get('anchor_name', f'anchor_{room_id}')
# 清理文件名中的非法字符
safe_anchor_name = re.sub(r'[<>:"/\|?*]', '_', anchor_name)
session_id = f"auto_record_{room_id}_{int(time.time())}"
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
# 使用主播名字命名文件
output_path = f"recordings/{safe_anchor_name}_{timestamp}.mp4"
# 启动录制线程
thread = threading.Thread(
target=record_stream,
args=(stream_url, output_path, session_id),
daemon=True
)
thread.start()
with self.lock:
self.polling_rooms[room_id]['recording_session_id'] = session_id
logger.info(f"已为主播 {anchor_name} (房间 {room_id}) 启动自动录制,会话ID: {session_id},文件: {output_path}")
except Exception as e:
logger.error(f"启动直播间 {room_id} 录制失败: {str(e)}")
def _stop_recording(self, room_id):
"""停止录制"""
try:
with self.lock:
session_id = self.polling_rooms[room_id]['recording_session_id']
if session_id:
self.polling_rooms[room_id]['recording_session_id'] = None
if session_id:
# 停止录制会话
with recording_lock:
if session_id in recording_sessions:
session = recording_sessions[session_id]
if session['process']:
session['process'].terminate()
session['status'] = 'stopped'
session['end_time'] = datetime.now()
logger.info(f"已停止直播间 {room_id} 的录制,会话ID: {session_id}")
except Exception as e:
logger.error(f"停止直播间 {room_id} 录制失败: {str(e)}")
def get_status(self):
"""获取所有轮询状态"""
with self.lock:
# 过滤掉不能JSON序列化的对象(如Thread)
status = {}
for room_id, room_info in self.polling_rooms.items():
status[room_id] = {
'room_url': room_info['room_url'],
'room_id': room_info['room_id'],
'check_interval': room_info['check_interval'],
'auto_record': room_info['auto_record'],
'status': room_info['status'],
'last_check': room_info['last_check'].isoformat() if room_info['last_check'] else None,
'stream_url': room_info['stream_url'],
'recording_session_id': room_info['recording_session_id'],
'anchor_name': room_info.get('anchor_name', f'anchor_{room_id}'), # 新增:主播名字
'live_title': room_info.get('live_title', ''), # 新增:直播标题
'added_time': room_info.get('added_time').isoformat() if room_info.get('added_time') else None, # 新增:添加时间
'online_count': room_info.get('online_count', 0), # 新增:在线人数
'viewer_count_text': room_info.get('viewer_count_text', '') # 新增:观看人数文本
# 注意:我们不包含 'thread' 字段,因为它不能JSON序列化
}
return status
def _add_to_history(self, room_id, room_url, action, description, anchor_name=None):
"""添加记录到历史(简化版,带去重功能)"""
# 获取主播名字,优先使用参数,其次从房间信息中获取
if not anchor_name:
with self.lock:
if room_id in self.polling_rooms:
anchor_name = self.polling_rooms[room_id].get('anchor_name', f'anchor_{room_id}')
else:
anchor_name = f'anchor_{room_id}'
# 检查是否已存在相同的链接(去重)
existing_urls = {record['room_url'] for record in self.polling_history}
if room_url in existing_urls:
logger.info(f"历史记录去重: 链接 {room_url} 已存在,跳过添加")
return
history_record = {
'id': f"{room_id}_{int(time.time()*1000)}", # 唯一ID
'anchor_name': anchor_name,
'room_url': room_url,
'timestamp': datetime.now().isoformat(),
'date': datetime.now().strftime('%Y-%m-%d'),
'time': datetime.now().strftime('%H:%M:%S')
}
# 添加到历史列表的开头(最新的在前面)
self.polling_history.insert(0, history_record)
# 保持历史记录数量在限制内
if len(self.polling_history) > self.max_history_records:
self.polling_history = self.polling_history[:self.max_history_records]
# 保存历史记录到文件
self._save_history_to_file()
logger.info(f"历史记录: {description} (房间 {room_id}),主播: {anchor_name}")
def get_history(self, limit=50, room_id=None, action=None):
"""获取历史记录"""
with self.lock:
history = self.polling_history.copy()
# 限制返回数量
return history[:limit]
def _save_rooms_to_file(self):
"""保存直播间列表到文件"""
try:
rooms_data = {}
for room_id, room_info in self.polling_rooms.items():
rooms_data[room_id] = {
'room_url': room_info['room_url'],
'check_interval': room_info['check_interval'],
'auto_record': room_info['auto_record'],
'anchor_name': room_info.get('anchor_name', f'anchor_{room_id}'),
'added_time': room_info['added_time'].isoformat() if room_info.get('added_time') else datetime.now().isoformat()
}
with open(self.rooms_file, 'w', encoding='utf-8') as f:
json.dump(rooms_data, f, ensure_ascii=False, indent=2)
logger.info(f"已保存 {len(rooms_data)} 个直播间到 {self.rooms_file}")
except Exception as e:
logger.error(f"保存直播间列表失败: {str(e)}")
def _load_rooms_from_file(self):
"""从文件加载直播间列表"""
try:
if os.path.exists(self.rooms_file):
with open(self.rooms_file, 'r', encoding='utf-8') as f:
rooms_data = json.load(f)
for room_id, room_info in rooms_data.items():
# 使用加载的数据创建直播间信息
self.polling_rooms[room_id] = {
'room_url': room_info['room_url'],
'room_id': room_id,
'check_interval': room_info.get('check_interval', 60),
'auto_record': room_info.get('auto_record', False),
'status': 'waiting',
'last_check': None,
'stream_url': None,
'recording_session_id': None,
'thread': None,
'anchor_name': room_info.get('anchor_name', f'anchor_{room_id}'),
'live_title': '',
'added_time': datetime.fromisoformat(room_info.get('added_time', datetime.now().isoformat())),
'history_added': False, # 加载的房间也需要添加历史记录(如果能获取到真实主播名字)
'online_count': room_info.get('online_count', 0), # 新增:在线人数
'viewer_count_text': room_info.get('viewer_count_text', '') # 新增:观看人数文本
}
# 启动轮询线程
thread = threading.Thread(
target=self._poll_room,
args=(room_id,),
daemon=True
)
thread.start()
self.polling_rooms[room_id]['thread'] = thread
logger.info(f"从 {self.rooms_file} 加载了 {len(rooms_data)} 个直播间")
else:
logger.info(f"直播间配置文件 {self.rooms_file} 不存在,将创建新文件")
except Exception as e:
logger.error(f"加载直播间列表失败: {str(e)}")
def _save_history_to_file(self):
"""保存历史记录到文件"""
try:
with open(self.history_file, 'w', encoding='utf-8') as f:
json.dump(self.polling_history, f, ensure_ascii=False, indent=2)
logger.debug(f"已保存历史记录到 {self.history_file}")
except Exception as e:
logger.error(f"保存历史记录失败: {str(e)}")
def _load_history_from_file(self):
"""从文件加载历史记录(带去重功能)"""
try:
if os.path.exists(self.history_file):
with open(self.history_file, 'r', encoding='utf-8') as f:
raw_history = json.load(f)
# 去重处理:根据 room_url 去重,保留最新的记录
seen_urls = set()
deduped_history = []
for record in raw_history:
room_url = record.get('room_url', '')
if room_url not in seen_urls:
seen_urls.add(room_url)
deduped_history.append(record)
else:
logger.debug(f"去重: 跳过重复链接 {room_url}")
self.polling_history = deduped_history
# 如果去重后数量有变化,保存文件
if len(deduped_history) != len(raw_history):
logger.info(f"历史记录去重: 从 {len(raw_history)} 条去重到 {len(deduped_history)} 条")
self._save_history_to_file()
logger.info(f"从 {self.history_file} 加载了 {len(self.polling_history)} 条历史记录")
else:
logger.info(f"历史记录文件 {self.history_file} 不存在,将创建新文件")
except Exception as e:
logger.error(f"加载历史记录失败: {str(e)}")
def stop_all(self):
"""停止所有轮询"""
self.running = False
with self.lock:
for room_id in list(self.polling_rooms.keys()):
self.remove_room(room_id)全局轮询管理器实例
multi_poller = MultiRoomPoller()
def record_stream(stream_url, output_path, session_id):
"""
使用 FFmpeg 录制直播流(支持分段录制)
:param stream_url: 直播流地址
:param output_path: 输出文件路径(不含分段序号)
:param session_id: 录制会话ID
"""
try:
logger.info(f"开始录制会话 {session_id}: {stream_url}")
# 创建录制目录
os.makedirs(os.path.dirname(output_path), exist_ok=True)
# 更新录制会话状态
with recording_lock:
recording_sessions[session_id] = {
'process': None,
'output_path': output_path,
'start_time': datetime.now(),
'stream_url': stream_url,
'status': 'recording',
'segments': [],
'current_segment': 0
}
# 生成分段文件名模板
base_name = output_path.rsplit('.', 1)[0]
segment_template = f"{base_name}_part%03d.mp4"
logger.info(f"录制会话 {session_id} 输出路径: {output_path}")
logger.info(f"录制会话 {session_id} 分段模板: {segment_template}")
# 构建 FFmpeg 命令 - 使用正确的分段格式
if stream_url.endswith('.m3u8'):
cmd = [
'ffmpeg',
'-i', stream_url,
'-c', 'copy', # 复制流,不重新编码
'-bsf:a', 'aac_adtstoasc', # 音频流修复
'-f', 'segment', # 使用分段格式
'-segment_time', '1800', # 30分钟分段
'-segment_format', 'mp4', # 分段格式为MP4
'-reset_timestamps', '1', # 重置时间戳
'-segment_list_flags', 'live', # 实时分段列表
segment_template # 分段文件名模板
]
else:
cmd = [
'ffmpeg',
'-i', stream_url,
'-c', 'copy', # 复制流,不重新编码
'-f', 'segment', # 使用分段格式
'-segment_time', '1800', # 30分钟分段
'-segment_format', 'mp4', # 分段格式为MP4
'-reset_timestamps', '1', # 重置时间戳
'-segment_list_flags', 'live', # 实时分段列表
segment_template # 分段文件名模板
]
logger.info(f"FFmpeg 命令: {' '.join(cmd)}")
# 执行录制
process = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
universal_newlines=True
)
# 更新录制会话状态
with recording_lock:
recording_sessions[session_id]['process'] = process
# 等待进程结束或手动停止
stdout, stderr = process.communicate()
# 更新最终状态
with recording_lock:
if session_id in recording_sessions:
if process.returncode == 0:
recording_sessions[session_id]['status'] = 'completed'
logger.info(f"录制会话 {session_id} 成功完成")
else:
recording_sessions[session_id]['status'] = 'failed'
recording_sessions[session_id]['error'] = stderr
logger.error(f"录制会话 {session_id} 失败: {stderr}")
recording_sessions[session_id]['end_time'] = datetime.now()
except Exception as e:
logger.error(f"录制会话 {session_id} 异常: {str(e)}")
with recording_lock:
if session_id in recording_sessions:
recording_sessions[session_id]['status'] = 'failed'
recording_sessions[session_id]['error'] = str(e)
recording_sessions[session_id]['end_time'] = datetime.now()@app.route('/api/record/start', methods=['POST'])
@handle_exceptions
def start_recording():
"""
开始录制直播流
"""
data = request.get_json()
stream_url = data.get('stream_url')
session_id = data.get('sessionid') or f"recording{int(time.time())}"
anchor_name = data.get('anchor_name', 'unknown_anchor') # 新增:主播名字参数
if not stream_url:
return jsonify({
'success': False,
'message': '缺少直播流地址'
})
# 检查是否已在录制
with recording_lock:
if session_id in recording_sessions and recording_sessions[session_id]['status'] == 'recording':
return jsonify({
'success': False,
'message': '该会话已在录制中'
})
# 清理文件名中的非法字符
safe_anchor_name = re.sub(r'[<>:"/\\|?*]', '_', anchor_name)
# 生成输出文件路径(使用主播名字)
timestamp = datetime.now().strftime('%Y%m%d_%H%M%S')
output_path = f"recordings/{safe_anchor_name}_{timestamp}.mp4"
# 启动录制线程
thread = threading.Thread(
target=record_stream,
args=(stream_url, output_path, session_id),
daemon=True
)
thread.start()
return jsonify({
'success': True,
'session_id': session_id,
'output_path': output_path,
'message': '录制已开始'
})@app.route('/api/record/stop', methods=['POST'])
@handle_exceptions
def stop_recording():
"""
停止录制
"""
data = request.get_json()
session_id = data.get('session_id')
if not session_id:
return jsonify({
'success': False,
'message': '缺少会话ID'
})
with recording_lock:
if session_id not in recording_sessions:
return jsonify({
'success': False,
'message': '找不到录制会话'
})
session = recording_sessions[session_id]
if session['status'] != 'recording':
return jsonify({
'success': False,
'message': f'会话状态为 {session["status"]}, 无法停止'
})
# 终止 FFmpeg 进程
try:
session['process'].terminate()
session['status'] = 'stopped'
session['end_time'] = datetime.now()
logger.info(f"已停止录制会话 {session_id}")
except Exception as e:
logger.error(f"停止录制会话 {session_id} 失败: {str(e)}")
return jsonify({
'success': False,
'message': f'停止录制失败: {str(e)}'
})
return jsonify({
'success': True,
'message': '录制已停止'
})@app.route('/api/get_current_stream', methods=['GET'])
@handle_exceptions
def get_current_stream():
"""
获取当前最新的直播流地址
"""
import os
stream_file = 'current_stream.txt'
if os.path.exists(stream_file):
try:
with open(stream_file, 'r', encoding='utf-8') as f:
stream_url = f.read().strip()
if stream_url:
logger.info(f"读取到当前直播流地址: {stream_url}")
return jsonify({
'success': True,
'stream_url': stream_url,
'message': '成功获取直播流地址'
})
else:
return jsonify({
'success': False,
'message': '直播流文件为空'
})
except Exception as e:
logger.error(f"读取直播流文件失败: {str(e)}")
return jsonify({
'success': False,
'message': f'读取文件失败: {str(e)}'
})
else:
return jsonify({
'success': False,
'message': '直播流文件不存在'
})@app.route('/api/record/split', methods=['POST'])
@handle_exceptions
def split_recording():
"""
手动分段录制
"""
data = request.get_json()
session_id = data.get('session_id')
if not session_id:
return jsonify({
'success': False,
'message': '缺少会话ID'
})
with recording_lock:
if session_id not in recording_sessions:
return jsonify({
'success': False,
'message': '找不到录制会话'
})
session = recording_sessions[session_id]
if session['status'] != 'recording':
return jsonify({
'success': False,
'message': f'会话状态为 {session["status"]}, 无法分段'
})
# 向 FFmpeg 进程发送分割信号
try:
# FFmpeg 的 segment 功能会自动创建新分段,这里只需记录操作
session['current_segment'] += 1
logger.info(f"已为录制会话 {session_id} 创建新分段 {session['current_segment']}")
return jsonify({
'success': True,
'message': f'已创建新分段 {session["current_segment"]}',
'segment_number': session['current_segment']
})
except Exception as e:
logger.error(f"分段录制会话 {session_id} 失败: {str(e)}")
return jsonify({
'success': False,
'message': f'分段失败: {str(e)}'
})@app.route('/api/poll', methods=['POST'])
@handle_exceptions
def poll_live_stream():
data = request.get_json()
live_url = data.get('live_url')
logger.info(f"收到轮询请求,直播间地址: {live_url}")
# 检查URL是否有效
if not live_url:
logger.warning("轮询请求中URL为空")
return jsonify({
'success': False,
'message': '直播间地址为空'
})
# 处理不同格式的输入
processed_url = live_url.strip()
# 1. 检查是否是纯数字(主播ID)
if re.match(r'^\d+$', processed_url):
logger.info(f"检测到主播ID格式: {processed_url}")
room_id = processed_url
full_url = f"https://live.douyin.com/{room_id}"
# 2. 检查是否是完整的抖音直播URL
elif "douyin.com" in processed_url:
logger.info(f"检测到抖音URL格式: {processed_url}")
# 提取房间号
room_id_match = re.search(r'live\.douyin\.com\/([^/?]+)', processed_url)
if room_id_match:
room_id = room_id_match.group(1)
full_url = f"https://live.douyin.com/{room_id}"
else:
# 尝试从URL路径中提取最后一部分
url_parts = processed_url.split('/')
room_id = url_parts[-1] or url_parts[-2]
full_url = processed_url
# 3. 其他格式(可能是短链接或其他标识符)
else:
logger.info(f"未识别的URL格式,尝试直接使用: {processed_url}")
room_id = processed_url
full_url = processed_url
logger.info(f"处理后的房间ID: {room_id}, 完整URL: {full_url}")
# 检查主播是否开播
try:
is_live = check_anchor_status(room_id)
# 如果检测为未开播,但用户确认已开播,增加额外检查
if not is_live:
logger.warning(f"初步检测主播 {room_id} 未开播,进行二次验证")
# 增加等待时间
time.sleep(5)
# 再次检查
is_live = check_anchor_status(room_id)
# 如果检测到开播,尝试解析直播流地址
stream_url = None
if is_live:
logger.info(f"检测到主播 {room_id} 正在直播,开始解析直播流地址")
try:
stream_url = get_real_stream_url(full_url)
if stream_url:
logger.info(f"成功解析直播流地址: {stream_url}")
else:
logger.warning(f"无法解析直播流地址,但主播确实在直播")
except Exception as parse_error:
logger.error(f"解析直播流地址异常: {str(parse_error)}")
# 解析失败不影响轮询结果,只是记录日志
logger.info(f"最终轮询结果: 主播 {room_id} {'正在直播' if is_live else '未开播'}")
# 按照API接口规范返回数据
response_data = {
'success': True,
'message': '轮询请求已处理',
'data': {
'live_url': live_url,
'is_live': is_live,
'room_id': room_id,
'full_url': full_url
}
}
# 如果解析到了直播流地址,添加到返回数据中
if stream_url:
response_data['data']['stream_url'] = stream_url
return jsonify(response_data)
except Exception as e:
logger.error(f"轮询处理异常: {str(e)}")
return jsonify({
'success': False,
'message': f'轮询处理异常: {str(e)}',
'live_url': live_url
})@app.route('/api/record/status', methods=['GET'])
@handle_exceptions
def get_recording_status():
"""
获取录制状态
"""
session_id = request.args.get('session_id')
if session_id:
with recording_lock:
if session_id in recording_sessions:
session = recording_sessions[session_id]
return jsonify({
'success': True,
'session_id': session_id,
'status': session['status'],
'output_path': session.get('output_path'),
'start_time': session.get('start_time'),
'end_time': session.get('end_time'),
'stream_url': session.get('stream_url')
})
else:
return jsonify({
'success': False,
'message': '找不到录制会话'
})
else:
# 返回所有录制会话状态
with recording_lock:
sessions = {
sid: {
'status': session['status'],
'output_path': session.get('output_path'),
'start_time': session.get('start_time'),
'end_time': session.get('end_time'),
'stream_url': session.get('stream_url')
}
for sid, session in recording_sessions.items()
}
return jsonify({
'success': True,
'sessions': sessions
})@app.route('/api/multi-poll/add', methods=['POST'])
@handle_exceptions
def add_polling_room():
"""添加直播间到轮询列表"""
data = request.get_json()
room_url = data.get('room_url')
room_id = data.get('room_id')
check_interval = data.get('check_interval', 60) # 默认60秒检查一次
auto_record = data.get('auto_record', False) # 是否自动录制
if not room_url:
return jsonify({
'success': False,
'message': '缺少直播间地址'
})
# 如果没有提供room_id,尝试从 URL解析
if not room_id:
# 处理不同格式的输入
processed_url = room_url.strip()
logger.info(f"尝试解析URL: {processed_url}")
# 1. 检查是否是纯数字(主播ID)
if re.match(r'^\d+$', processed_url):
logger.info(f"检测到主播ID格式: {processed_url}")
room_id = processed_url
# 2. 检查是否是完整的抖音直播URL
elif "douyin.com" in processed_url:
logger.info(f"检测到抖音URL格式: {processed_url}")
# 尝试多种URL格式的解析
# 格式1: https://live.douyin.com/123456
room_id_match = re.search(r'live\.douyin\.com/([^/?&#]+)', processed_url)
if room_id_match:
room_id = room_id_match.group(1)
logger.info(f"从live.douyin.com URL提取房间ID: {room_id}")
else:
# 格式2: https://www.douyin.com/user/MS4wLjABAAAA...
user_id_match = re.search(r'/user/([^/?&#]+)', processed_url)
if user_id_match:
room_id = user_id_match.group(1)
logger.info(f"从用户主页URL提取用户ID: {room_id}")
else:
# 格式3: 尝试从URL路径中提取数字部分
url_parts = processed_url.split('/')
for part in reversed(url_parts):
if part and part != '' and not part.startswith('?'):
# 移除可能的参数
clean_part = part.split('?')[0].split('#')[0]
if clean_part:
# 如果是纯数字,直接使用
if re.match(r'^\d+$', clean_part):
room_id = clean_part
logger.info(f"从URL路径提取房间ID: {room_id}")
break
# 否则使用完整的部分
else:
room_id = clean_part
logger.info(f"从URL路径提取标识符: {room_id}")
break
if not room_id:
return jsonify({
'success': False,
'message': f'无法从 URL解析房间ID: {processed_url}'
})
# 3. 其他格式(可能是短链接或其他标识符)
else:
logger.info(f"未识别的URL格式,尝试直接使用: {processed_url}")
room_id = processed_url
logger.info(f"最终解析得到的房间ID: {room_id}")
success = multi_poller.add_room(room_id, room_url, check_interval, auto_record)
if success:
return jsonify({
'success': True,
'message': f'已添加直播间 {room_id} 到轮询列表',
'room_id': room_id
})
else:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 已在轮询列表中'
})@app.route('/api/multi-poll/remove', methods=['POST'])
@handle_exceptions
def remove_polling_room():
"""从轮询列表移除直播间"""
data = request.get_json()
room_id = data.get('room_id')
if not room_id:
return jsonify({
'success': False,
'message': '缺少房间ID'
})
success = multi_poller.remove_room(room_id)
if success:
return jsonify({
'success': True,
'message': f'已移除直播间 {room_id}'
})
else:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 不在轮询列表中'
})@app.route('/api/multi-poll/status', methods=['GET'])
@handle_exceptions
def get_multi_polling_status():
"""获取多直播间轮询状态"""
status = multi_poller.get_status()
return jsonify({
'success': True,
'polling_rooms': status,
'total_rooms': len(status)
})@app.route('/api/multi-poll/history', methods=['GET'])
@handle_exceptions
def get_polling_history():
"""获取轮询历史记录"""
获取查询参数
limit = request.args.get('limit', 50, type=int)
room_id = request.args.get('room_id')
action = request.args.get('action')
# 限制limit的范围
limit = min(max(1, limit), 200) # 限制在1-200之间
history = multi_poller.get_history(limit=limit, room_id=room_id, action=action)
return jsonify({
'success': True,
'history': history,
'total_records': len(history),
'filters': {
'limit': limit,
'room_id': room_id,
'action': action
}
})@app.route('/api/multi-poll/start-record', methods=['POST'])
@handle_exceptions
def start_manual_recording():
"""手动为指定直播间启动录制"""
data = request.get_json()
room_id = data.get('room_id')
if not room_id:
return jsonify({
'success': False,
'message': '缺少房间ID'
})
status = multi_poller.get_status()
if room_id not in status:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 不在轮询列表中'
})
room_info = status[room_id]
if room_info['status'] != 'live' or not room_info['stream_url']:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 当前不在直播或无流地址'
})
if room_info['recording_session_id']:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 已在录制中'
})
# 启动录制
multi_poller._start_recording(room_id, room_info['stream_url'])
# 简化版:不记录手动录制
return jsonify({
'success': True,
'message': f'已为直播间 {room_id} 启动录制'
})@app.route('/api/multi-poll/stop-record', methods=['POST'])
@handle_exceptions
def stop_manual_recording():
"""手动停止指定直播间的录制"""
data = request.get_json()
room_id = data.get('room_id')
if not room_id:
return jsonify({
'success': False,
'message': '缺少房间ID'
})
status = multi_poller.get_status()
if room_id not in status:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 不在轮询列表中'
})
room_info = status[room_id]
if not room_info['recording_session_id']:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 当前未在录制'
})
# 停止录制
multi_poller._stop_recording(room_id)
# 简化版:不记录手动停止录制
return jsonify({
'success': True,
'message': f'已停止直播间 {room_id} 的录制'
})@app.route('/api/multi-poll/pause', methods=['POST'])
@handle_exceptions
def pause_polling_room():
"""暂停指定直播间的轮询"""
data = request.get_json()
room_id = data.get('room_id')
if not room_id:
return jsonify({
'success': False,
'message': '缺少房间ID'
})
success = multi_poller.pause_room(room_id)
if success:
return jsonify({
'success': True,
'message': f'已暂停直播间 {room_id} 的轮询'
})
else:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 不在轮询列表中或已暂停'
})@app.route('/api/multi-poll/resume', methods=['POST'])
@handle_exceptions
def resume_polling_room():
"""恢复指定直播间的轮询"""
data = request.get_json()
room_id = data.get('room_id')
if not room_id:
return jsonify({
'success': False,
'message': '缺少房间ID'
})
success = multi_poller.resume_room(room_id)
if success:
return jsonify({
'success': True,
'message': f'已恢复直播间 {room_id} 的轮询'
})
else:
return jsonify({
'success': False,
'message': f'直播间 {room_id} 不在轮询列表中或未暂停'
})if name == 'main':
创建录制目录
os.makedirs('recordings', exist_ok=True)
# 监听所有接口,允许外部访问
app.run(host='0.0.0.0', port=5000, debug=True)前端:
多直播间管理
直播播放器
轮询历史记录